本文共 3618 字,大约阅读时间需要 12 分钟。
如果提到HTML5的新API, ,大家应该比较熟悉。WebSocket是用于简述请求数量的新协议,Web Workers是用于实现浏览器的多线程。而今天要介绍的Service Worker是用于页面离线缓存,提供类似App的服务。注意,这和浏览器缓存不是一回事。
下面所有代码请查看下载完整版本
1. Service Worker 介绍
试想,当你正在访问一个人的博客目录,当你找到你感兴趣的博客时候,想点击进入查看完整博客,这时候断网了,你将会看到如下页面:
 忽略上面的网址,这是我在自己浏览器里使用chrome -> 开发者工具 -> New Work -> offline 模拟断网,访问我本地服务器上网页的结果。你看到页面应该类似。这时候仅仅依靠浏览器缓存是无法解决问题的。于是HTML5提出了 Service Worker,它是一段运行在浏览器后台进程里的脚本,它独立于当前页面,提供了那些不需要与web页面交互的功能在网页背后悄悄执行的能力。在将来,基于它可以实现消息推送,静默更新以及地理围栏等服务,但是目前它首先要具备的功能是拦截和处理网络请求,包括可编程的响应缓存管理。所以,使用它可以断网情况下轻松实现拦截用户请求,用已经缓存的页面代替服务器响应,简称离线缓存。 注意:Service Worker由于权限很高,只支持https协议或者localhost
忽略上面的网址,这是我在自己浏览器里使用chrome -> 开发者工具 -> New Work -> offline 模拟断网,访问我本地服务器上网页的结果。你看到页面应该类似。这时候仅仅依靠浏览器缓存是无法解决问题的。于是HTML5提出了 Service Worker,它是一段运行在浏览器后台进程里的脚本,它独立于当前页面,提供了那些不需要与web页面交互的功能在网页背后悄悄执行的能力。在将来,基于它可以实现消息推送,静默更新以及地理围栏等服务,但是目前它首先要具备的功能是拦截和处理网络请求,包括可编程的响应缓存管理。所以,使用它可以断网情况下轻松实现拦截用户请求,用已经缓存的页面代替服务器响应,简称离线缓存。 注意:Service Worker由于权限很高,只支持https协议或者localhost 2. Service Worker使用
2.1 生命周期
先来看一下一个service worker的运行周期(图片来源:)
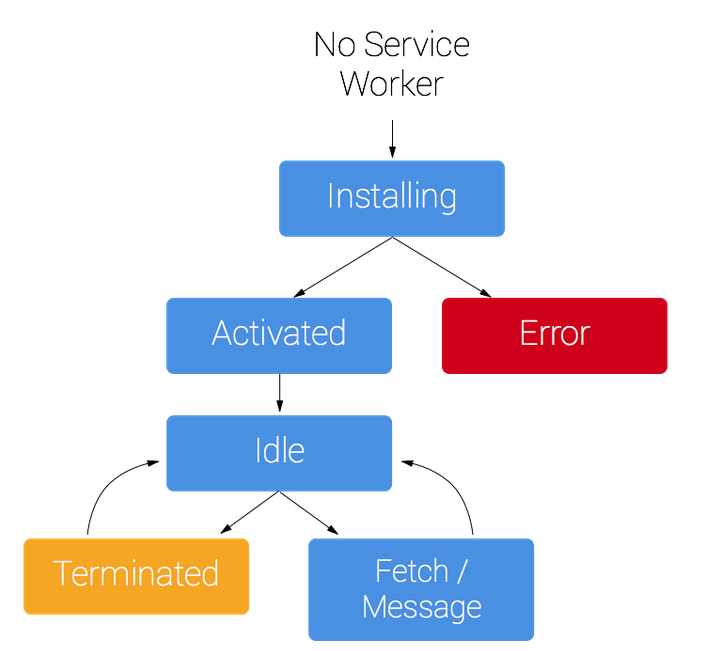 Service worker拥有一个完全独立于Web页面的生命周期。
Service worker拥有一个完全独立于Web页面的生命周期。 要让一个service worker在你的网站上生效,你需要先在你的网页中注册它。注册一个service worker之后,浏览器会在后台默默启动一个service worker的安装过程。
在安装过程中,浏览器会加载并缓存一些静态资源。如果所有的文件被缓存成功,service worker就安装成功了。如果有任何文件加载或缓存失败,那么安装过程就会失败,service worker就不能被激活(也即没能安装成功)。如果发生这样的问题,别担心,它会在下次再尝试安装。
当安装完成后,service worker的下一步是激活,在这一阶段,你还可以升级一个service worker的版本,具体内容我们会在后面讲到。
在激活之后,service worker将接管所有在自己管辖域范围内的页面,但是如果一个页面是刚刚注册了service worker,那么它这一次不会被接管,到下一次加载页面的时候,service worker才会生效。
当service worker接管了页面之后,它可能有两种状态:要么被终止以节省内存,要么会处理fetch和message事件,这两个事件分别产生于一个网络请求出现或者页面上发送了一个消息。
总结起来Service Worker的生命周期有如下几个关键步骤(就是常常需要监听并制定回调函数的事件):
1. 安装 2. 激活,激活成功之后,打开chrome://inspect/#service-workers可以查看到当前运行的service worker 3. 监听fetch和message事件,下面两种事件会进行简要描述 4. 销毁,是否销毁由浏览器决定,如果一个service worker长期不使用或者机器内存有限,则可能会销毁这个worker 下面具体介绍这几个事件。2.2 生命周期中常需监听的几个事件
fetch事件
在页面发起http请求时,service worker可以通过fetch事件拦截请求,并且给出自己的响应。
w3c提供了一个新的fetch api,用于取代XMLHttpRequest,与XMLHttpRequest最大不同有两点:fetch()方法返回的是Promise对象,通过then方法进行连续调用,减少嵌套。ES6的Promise在成为标准之后,会越来越方便开发人员。
提供了Request、Response对象,如果做过后端开发,对Request、Response应该比较熟悉。前端要发起请求可以通过url发起,也可以使用Request对象发起,而且Request可以复用。但是Response用在哪里呢?在service worker出现之前,前端确实不会自己给自己发消息,但是有了service worker,就可以在拦截请求之后根据需要发回自己的响应,对页面而言,这个普通的请求结果并没有区别,这是Response的一处应用。
message事件
页面和serviceWorker之间可以通过posetMessage()方法发送消息,发送的消息可以通过message事件接收到。
这是一个双向的过程,页面可以发消息给service worker,service worker也可以发送消息给页面,由于这个特性,可以将service worker作为中间纽带,使得一个域名或者子域名下的多个页面可以自由通信。
install事件
当页面加载时触发该事件。常用于缓存离线页面,当断开网络时,在该事件中缓存的页面将被返回给用户。
acrive事件
当Service Worker被触发时触发该事件。代码更新后,通常需要在activate的callback中执行一个管理cache的操作。因为你会需要清除掉之前旧的数据。我们在activate而不是install的时候执行这个操作是因为如果我们在install的时候立马执行它,那么依然在运行的旧版本的数据就坏了。
3. Service Worker实例
再次提醒:下面所有代码请查看下载完整版本
例子很简单,当我在连接网络时访问页面,结果如下:
 控制台如下:
控制台如下: 
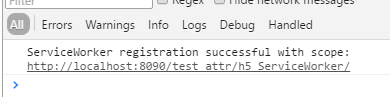 解释下这里的 scope,是指可以拦截请求的域。 当我在chrome里使用chrome -> 开发者工具 -> New Work -> offline 模拟断网,刷新页面:
解释下这里的 scope,是指可以拦截请求的域。 当我在chrome里使用chrome -> 开发者工具 -> New Work -> offline 模拟断网,刷新页面:  同一个网址,返回了不同页面。说明Service Worker成功拦截了原始请求(如果不拦截,会像上面那样出现页面无法访问的提示)。
同一个网址,返回了不同页面。说明Service Worker成功拦截了原始请求(如果不拦截,会像上面那样出现页面无法访问的提示)。 主要代码及注释如下:
index.htmltest service worker - online page 
您已经连接网络...
service-worker.js
'use strict';var cacheVersion = 0;var currentCache = { offline: 'offline-cache' + cacheVersion};const offlineUrl = 'offline.html';this.addEventListener('install', event => { event.waitUntil( caches.open(currentCache.offline).then(function(cache) { return cache.addAll([ './offline.svg', offlineUrl ]); }) );});this.addEventListener('fetch', event => { if (event.request.mode === 'navigate' || (event.request.method === 'GET' && event.request.headers.get('accept').includes('text/html'))) { event.respondWith( fetch(event.request.url).catch(error => { // Return the offline page return caches.match(offlineUrl); }) ); } else{ event.respondWith(caches.match(event.request) .then(function (response) { return response || fetch(event.request); }) ); }});